The Complexity of Compiled Models
These are some results from experiments measuring the LLC of Tracr models.
To summarize:
- Tracr models have finicky loss landscapes that make calculating the LLC difficult.
- 'Distilling' a Tracr model into a model of equal size or smaller dramatically smooths its loss landscape.
- Decreasing model size through distillation (training smaller models to match Tracr outputs) reveals significant LLC variation between models of different sizes.
- Increasing model size through direct compilation (compiling the same program with larger maximum sequence lengths) yields more consistent LLC estimates.
Tracr Programs Used:
We run experiments on the below Tracr programs, all sourced from the Tracr git repository. We use the estimate_learning_coeff function with SGLD from the devinterp library for all of these experiments. Note we do not use dyck-2 and dyck-3, as estimating their LLC was very difficult (more in 'appendix' + below)
| fn | 'rasp time' | theoretical time | description |
|---|---|---|---|
length | O(n²) | O(1) | outputs sequence length at each position |
frac_prevs | O(n²) | O(n) | fraction of previous tokens matching condition |
sort | O(n²) | O(n log n) | sorts with duplicate keys allowed |
sort_unique | O(n²) | O(n log n) | sorts with unique keys |
hist | O(n²) | O(n) | counts token frequencies |
sort_freq | O(n²) | O(n) | sorts by token frequency |
pair_balance | O(n²) | O(n) | tracks balance of open/close tokens |
| Not used: | |||
dyck-2 | O(n²) | O(n) | checks balanced () and {} |
dyck-3 | O(n²) | O(n) | checks balanced (), {}, and [] |
Note that 'rasp time' is always O(n²) because rasp makes extensive use of the select primitive, which creates an n×n selector matrix comparing every position with every other position.
First, we plot the LLC over compiled Tracr models of increasing size. We do this by increasing the 'Maximum Sequence Length' of the model, which scales the residual stream width and number of layers of our model. We calculate the LLC for models with sequence lengths between 4 and 100. Interestingly, we see some LLC's stay constant, some scale dramatically, and some drop.
We include lines indicating the 'Sparsity Ratio' of the model, which is .
LLC vs Sequence Length and Sparsity Ratio:
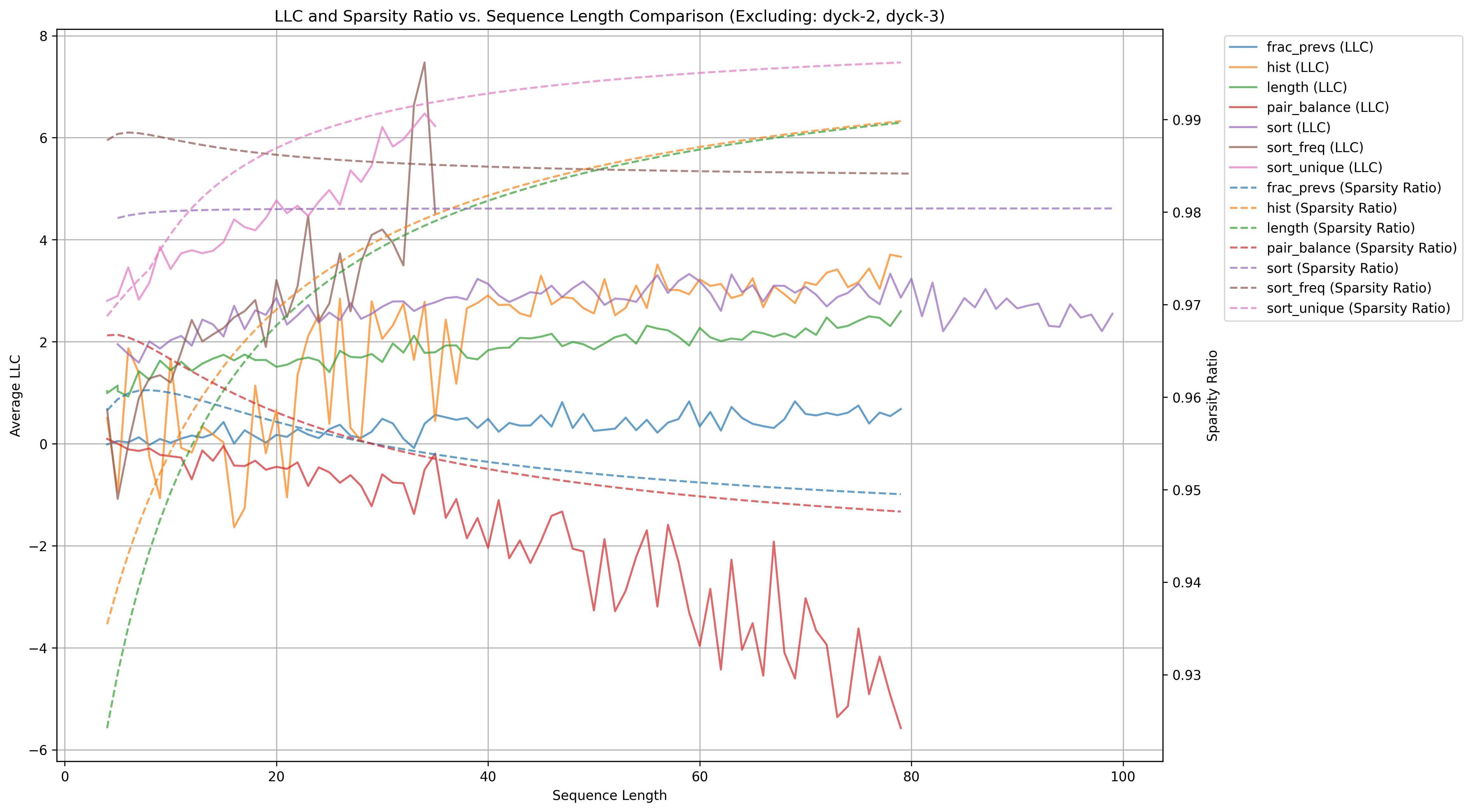
It may seem that the 'live params' lines track the LLC relatively well, with their final relative ordering being somewhat aligned with the ordering of the LLC's over multiple hyperparams. However, varying the SGLD learning rate does give slightly different relative orderings. I'm unsure how to compare the LLCs of these models, or how to identify what the 'correct' hyperparams are for a group of models. No clear inference with big O time can be drawn because of this.
Note that sort_unique and sort_freq data series are truncated in the above graph. They both explode later and skew the graph. Here is their full graph:
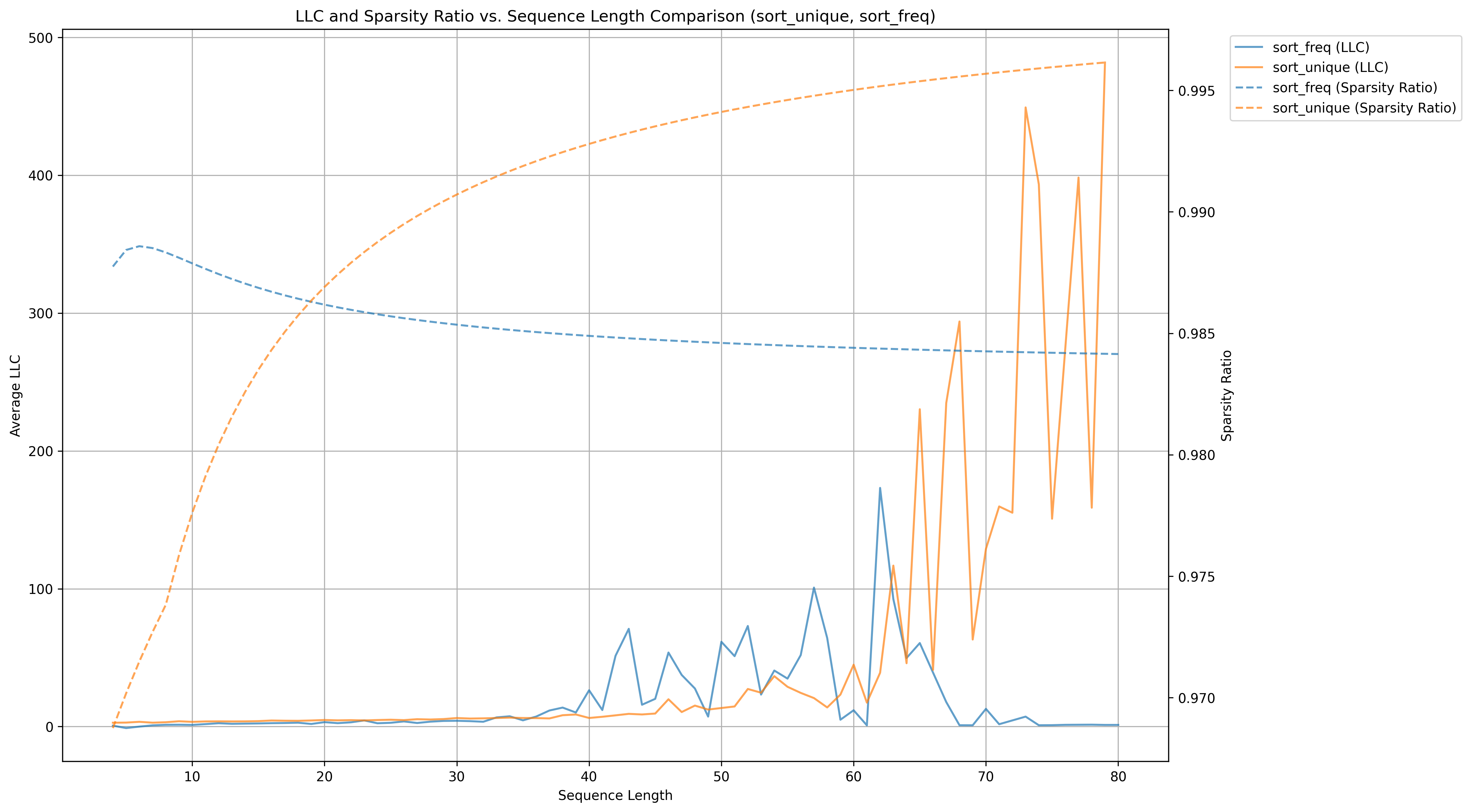
Choosing a lower lr will keep LLC's from exploding, but also seems to harm the LLC's of models that don't need such a low learning rate. The above choice of lr, 1e-5 seemed to be a good choise because most LLC's weren't negative and initially were sanely bounded.
Here is the same plot, but with a 1e-10 lr:
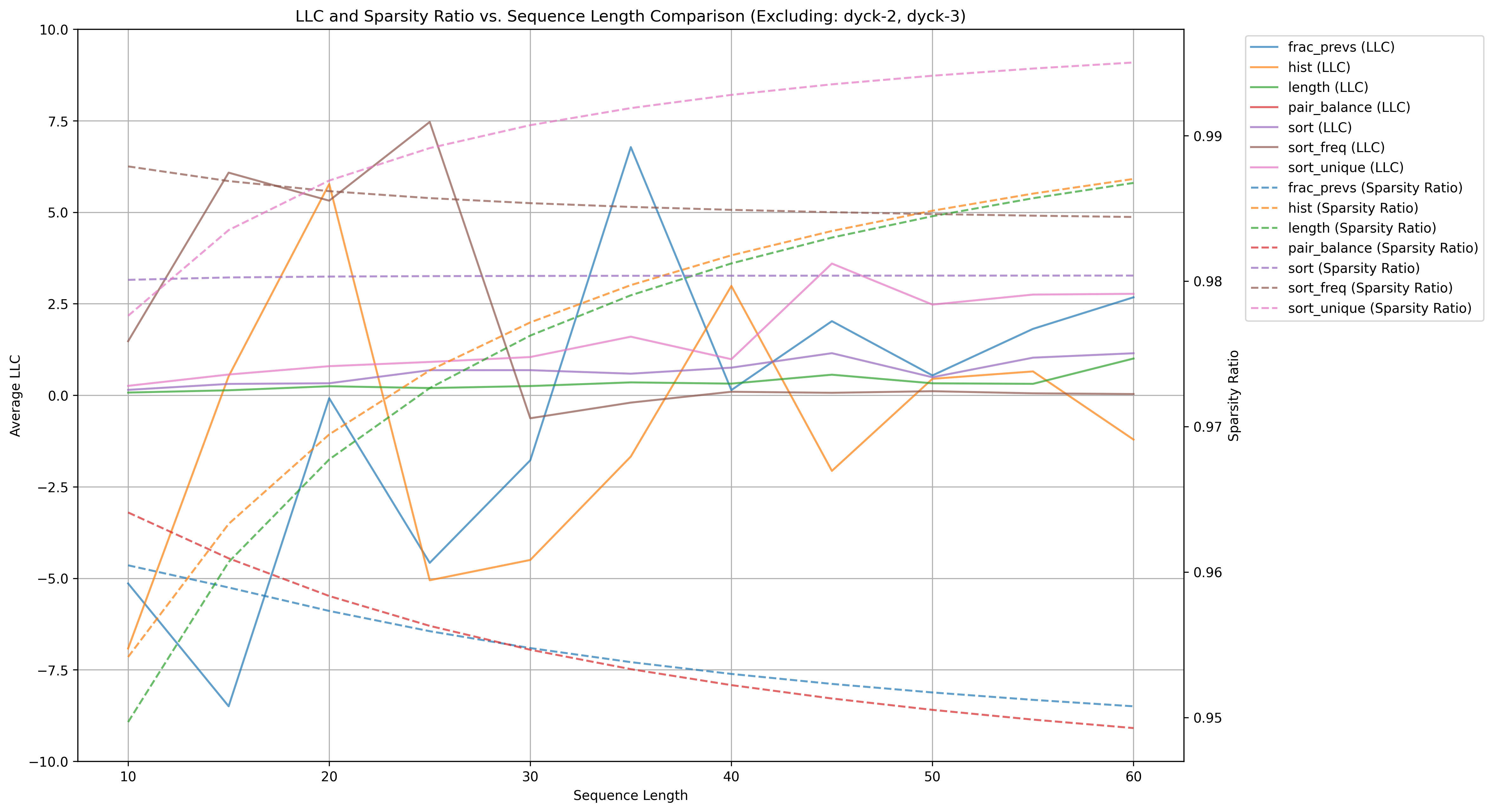
It's clear that some normalization of the SGLD hyperparams needs to happen as the models increase in parameter count, but why only some models need this is unclear. Trying with dynamic SGLD learning rates that were linear / quadratic functions of the param count, we found it wasn't a one size fits all kind of thing. To keep relative LLC's fair, all LLC's were calculated with the same hyperparams (1e-5 and default nbeta).
LLC of Distilled Models
It seems that distilling a TracR model into an equal or smaller model smooths the LLC Loss trace and gives more stable LLCs. It also seems to bring all TracR models into the same 'range' of LLC. I do this by minimizing the KL between the Tracr (teacher) logits and the student logits, because cross entropy wouldn't preserve the Tracr models 'correct but not confident logits' (Tracr logits are odd in the sense that they are always 'correct' but don't have confident logprobs. This is a result of how they are compiled). Below is a chart indicating the LLC of the original Tracr model, the LLC's of incrementally shrunk, distilled versions of the model (shrunk by a % along d_model and d_mlp),
Below we see Teacher LLC's over a wide range of values ~[1, 60], and when we distill most LLCs end up 0 and 2, with Hist and Pair Balance slightly negative.
Note the relative LLC ordering between tasks changes as we compress - Length has a higher Teacher LLC than Sort, but when distilled, has a lower LLC. My guess is that the Teacher LLC of Length was an overestimate, as the big O ordering of the distilled LLC's is closer to correct. Note: Because these models are distilled with KL from a Tracr model, their logprobs are also not 'confident'. I think that distilling works because the loss landscape of a Tracr model is super artificial.
LLC's of Teacher Models / Progressively Shrunk Distilled Models
| TASK | Teacher | 0% Shrunk | 48% Shrunk | 95% Shrunk | ~Restored KL? | Theoretical Big O |
|---|---|---|---|---|---|---|
| Sort Unique | 63.74 | 1.71 | 1.56 | 1.85 | Y | O(nlogn) |
| Sort | 16.79 | 1.77 | 1.43 | 1.52 | Y | O(nlogn) |
| Length | 35.89 | 0.95 | 0.77 | 0.76 | Y | O(1) |
| Frac Prevs | 1.01 | 0.81 | 0.73 | 0.79 | Y (N @95% Shrunk) | O(n) |
| Hist | -0.96 | 0 | -0.49 | 0.06 | N | O(n) |
| Pair Balance | -6.08 | -6.00 | -9.33 | -24.62 | N | O(n) |
| Sort Freq | 425.0 | -3.36 | -2.08 | -2.72 | Y | O(n) |
| Dyck-2 | NaN | - | - | - | - | - |
| Dyck-3 | NaN | - | - | - | - | - |
SGLD Loss Trace of Teacher vs Compressed Students
Sort Unique:
Sort:
Length:
Frac Prevs:
Hist:
Pair Balance:
Sort Freq:
Note: I was unable to attain traces for Dyck-2 and Dyck-3 due to exploding gradients and because distilling from them is a nightmare.
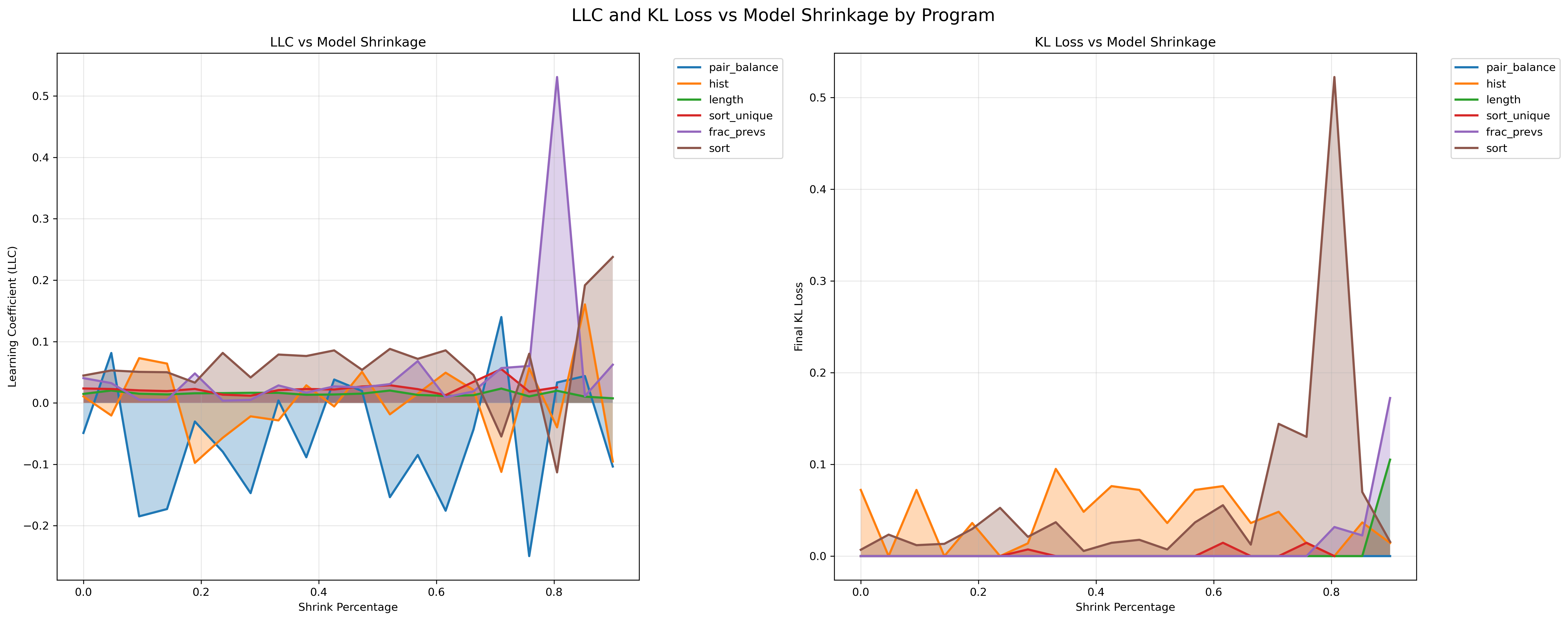
LLC vs Shrink %:
Looking at the stability of the LLC for different levels of compression ('shrink'), we see that for some values the LLC is noisy, while for length, frac_prevs, and sort_unique are remarkably stable. I think a more in-depth experiment, perhaps without making use of Tracr, could be good here. Each LLC sampling was done with 5 chains.
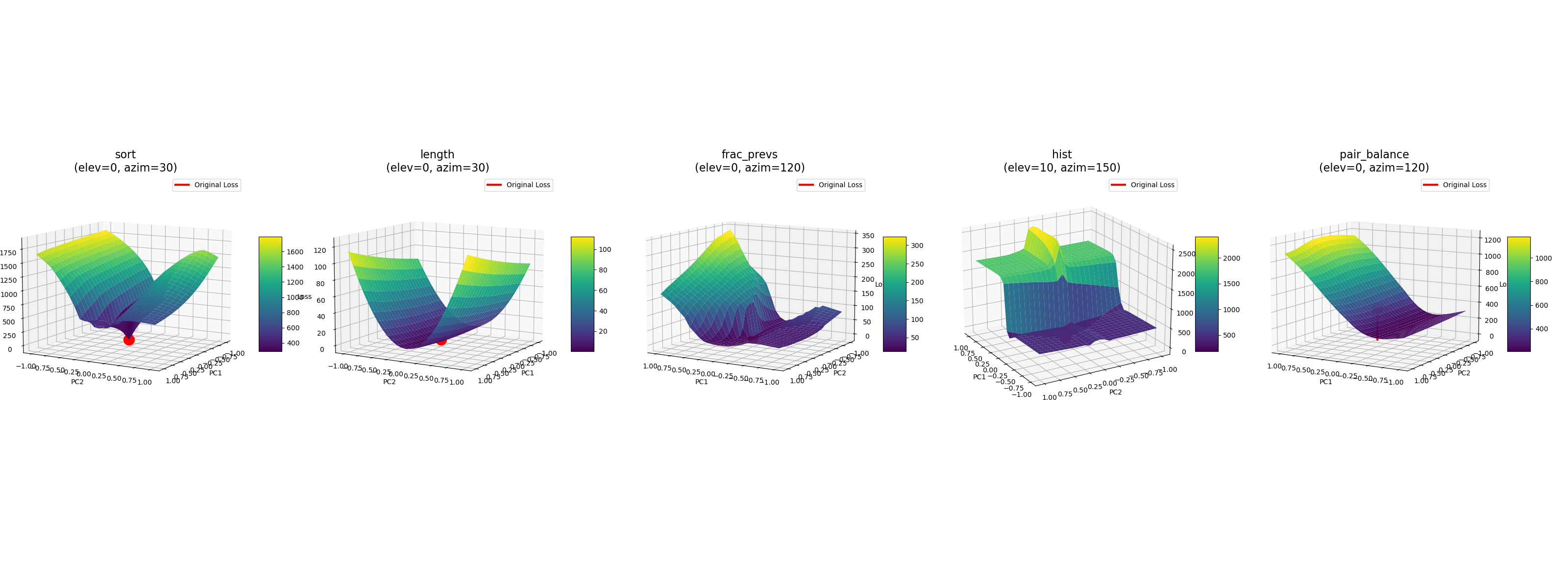
Landscape Visualization
Looking at the loss landscapes, visualized by perturbing weights along the top 2 principal components of the gradients, we see that the LLC's of the teacher models above seem to follow.
For instance, the trace of SGLD on pair_balance goes down, and looking at the loss landscape we can see that the starting weights were not at a local minima.
Similarly, the initial spike on the trace of hist's teacher LLC is likely due to SGLD exploring directly up the wall on the side of the starting weights, leading to a huge spike in loss, while the rest of its search is over a flat loss landscape. These loss landscapes also are much nicer than I expected, which is very cool.
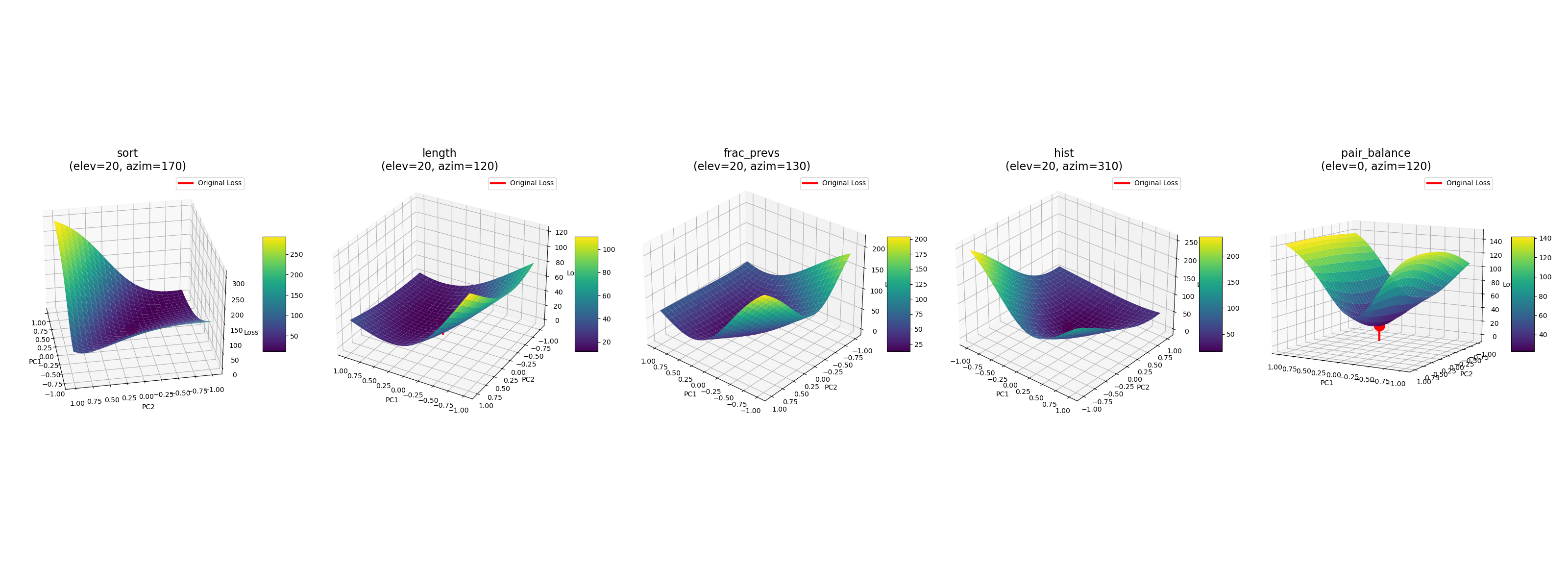
Loss Landscapes of 'Well Behaved' Tracr Models:
(sort, length, frac_prevs, hist, pair_balance)
Similarly, we can examine the loss landscapes of the models for which had 'badly' behaved LLCs.
Loss Landscapes of 'Badly Behaved' Tracr Models:
(sort_freq, dyck-2, dyck-3, sort_unique)
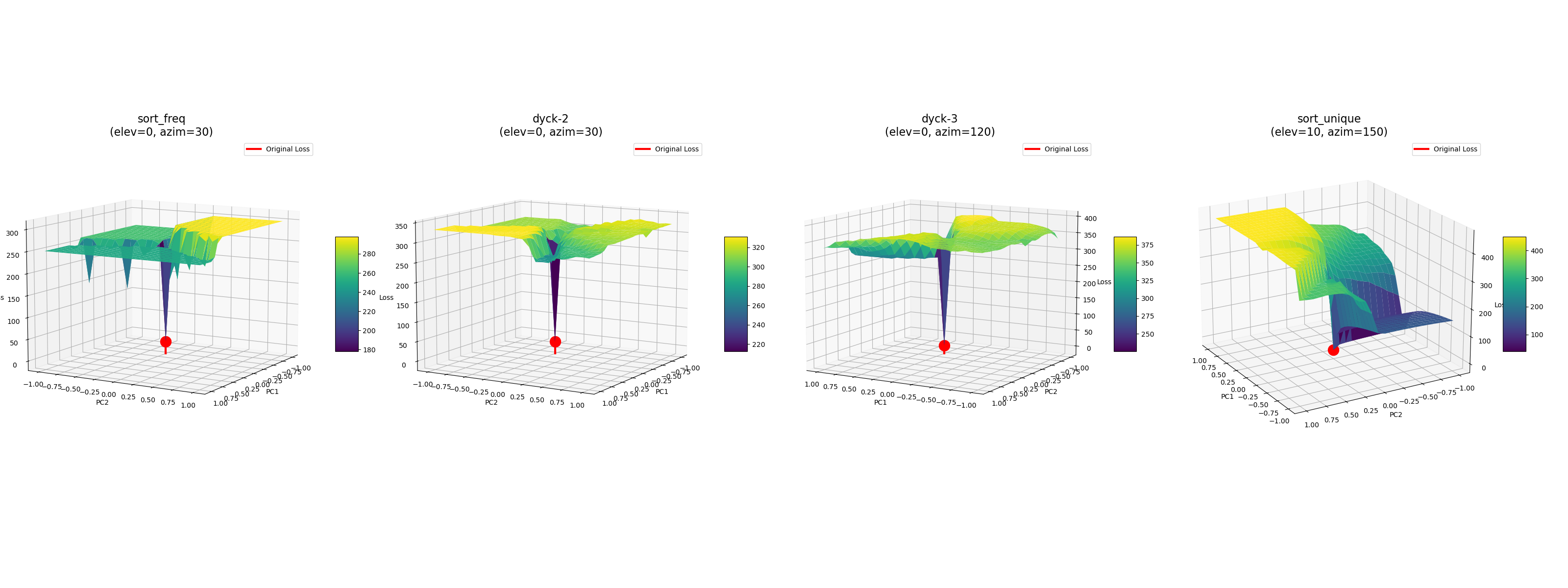
We see that their loss landscapes are terribly sharp in comparison! If I'm understanding the practicalities of the LLC here, this should explain why estimating the LLC didn't work well.
Furthermore, we can examine the loss landscapes of the distilled models. Distilling Tracr models into models of equivalent size / architecture, we get landscapes that are (expectedly) not nearly as sharp as their equivalent raw Tracr model.
Loss Landscapes of Distilled 'Well Behaved' Programs:
Loss Landscapes of Distilled 'Badly Behaved' Programs:
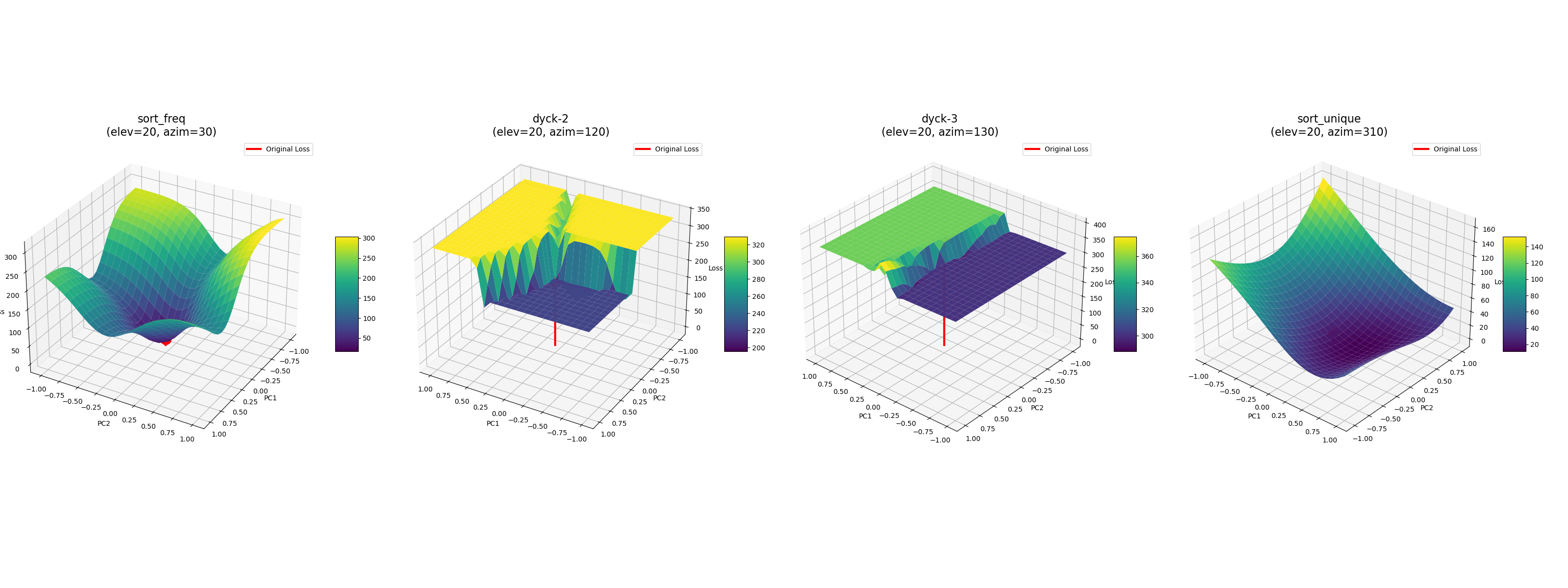
sort_freq and sort_unique distill into smooth landscapes whilst dyck-2 and dyck-3 are still contrived
Note on Dyck Models:
The Dyck Tracr models required an SGLD learning rate of 1e-12 to get anything like a reasonable LLC.
These were them at 1e-10:
1e-12:
1e-20 gave similar results.