Toy SAE's Trained on 'Orthogonal' Data, Results
Toy SAE's Trained on 'Orthogonal' Data, Results
These models were trained on binary feature vectors, where each feature fires randomly, with equal probability, and independently of other features. Also, note these models were trained without an encoder or decoder bias to aid interpretability of weights.
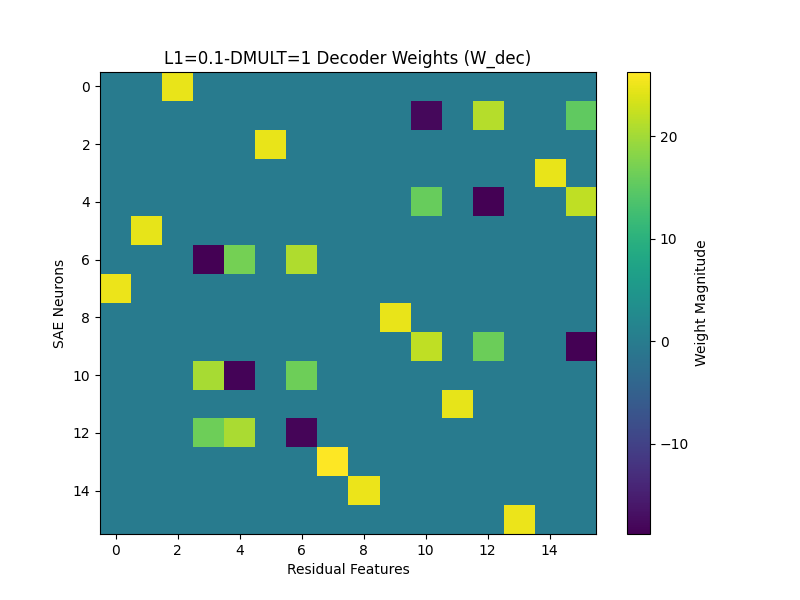
For a dictionary size of 1 (1:1 ratio with the input data), a model is able to successfully learn a 1:1 mapping of the input features when trained with the right L1 value. Because the features are independent, we can tell the model has learned a faithful representation when the decoder weights and hidden activations are all orthogonal.
For example, this model (dictionary size 1) has a Mean Max Cosine similarity between the decoder weights and the input data of 0.999:
.png)
.png)
The 'Cosine Similarity between Activations' graph shows the cosine similarity between hidden layer activations for each input feature. The graph is ~Identity, meaning different input features activate completely different hidden neurons. We also see that the hidden activations for each residual feature are ~a permutation of the identity—the model learned to assign each input feature to a single neuron, which is exactly what we want to see.
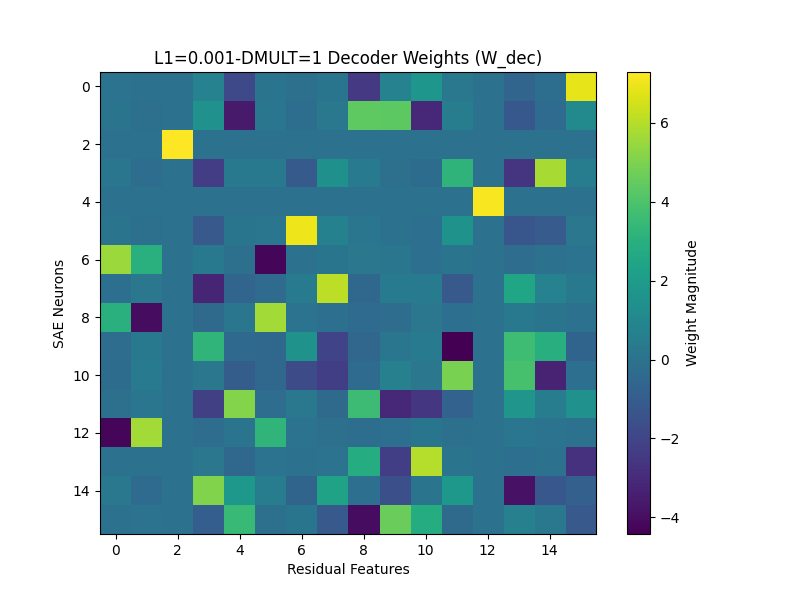
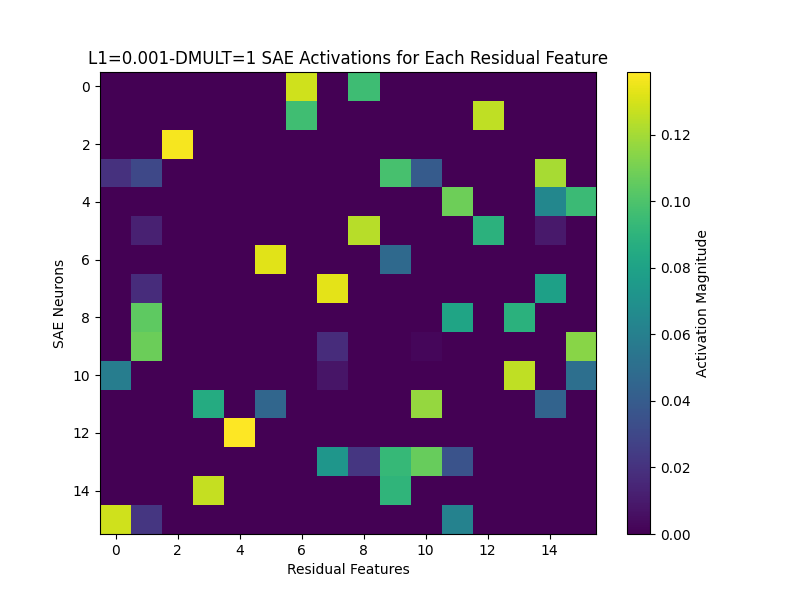
Here's an example of a model that failed to learn a faithful representation of the feature set—it had a much lower L1 coefficient, meaning it wasn't penalized as much for the magnitude of its hidden activations.
.png)
.png)
Looking at the activations and decoder weight graphs for this model, we can see that the model is putting features into superposition—some decoder weights look to multiple neurons in the hidden layer to reconstruct the input feature. Interestingly, we can see in the above graphs that the model is putting features 3, 4, and 6 into superposition, forming a triangle (Same for 10, 12, and 15). When decoding a feature in superposition, the decoder fires strongly negative on one feature out of the three (one 'vertex' of the triangle)—this negative firing negates the positive firing along the shared dimension of a mismatch. Note, when there's no superposition, the decoder weights will just be a scaled transpose of the hidden activations for each feature.
(The model putting features into superposition is not the same thing as feature splitting—the data is not correlated, so there should be no 'similarity' between features. Instead, the model is just trying to reduce L1 loss.)
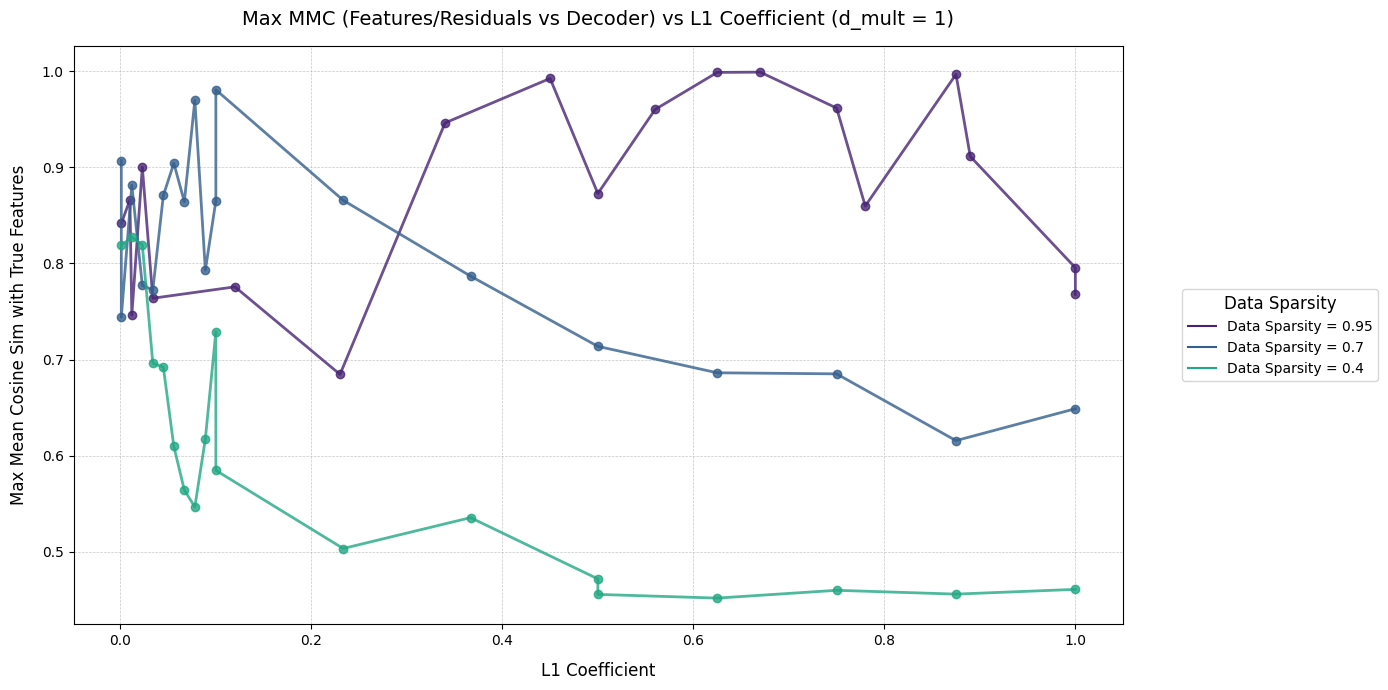
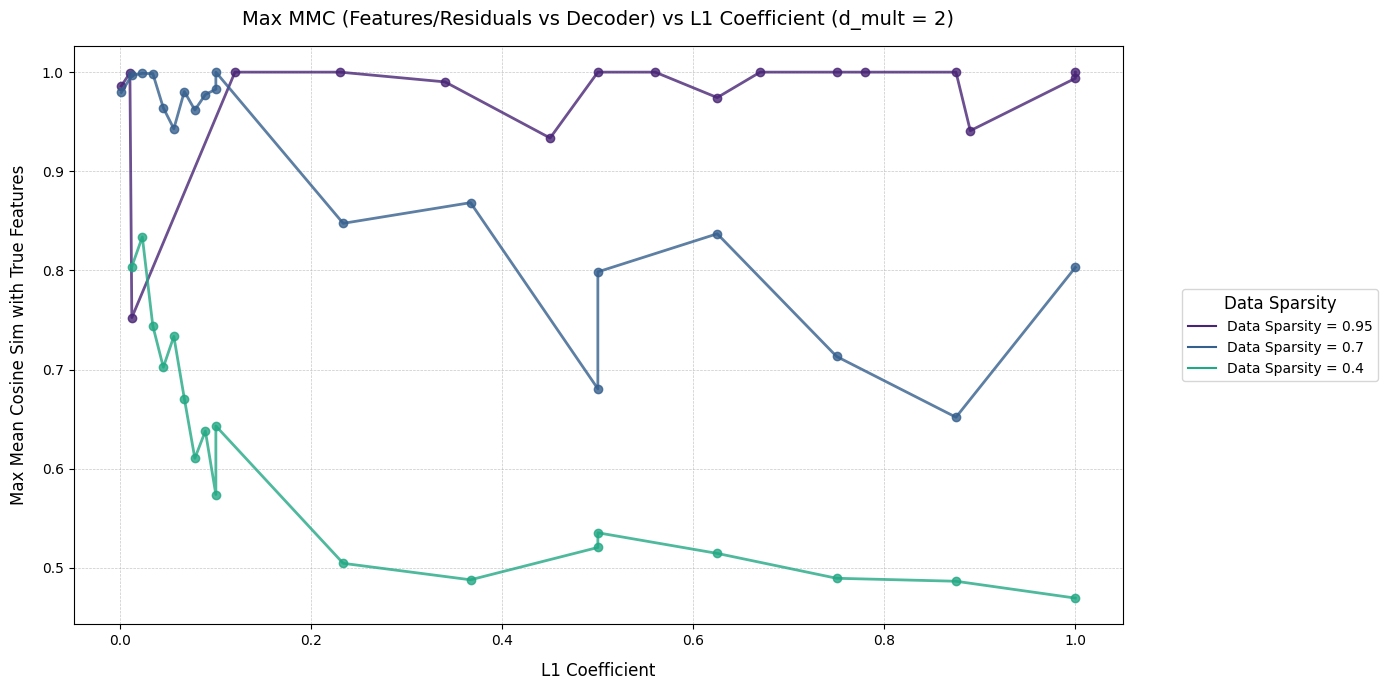
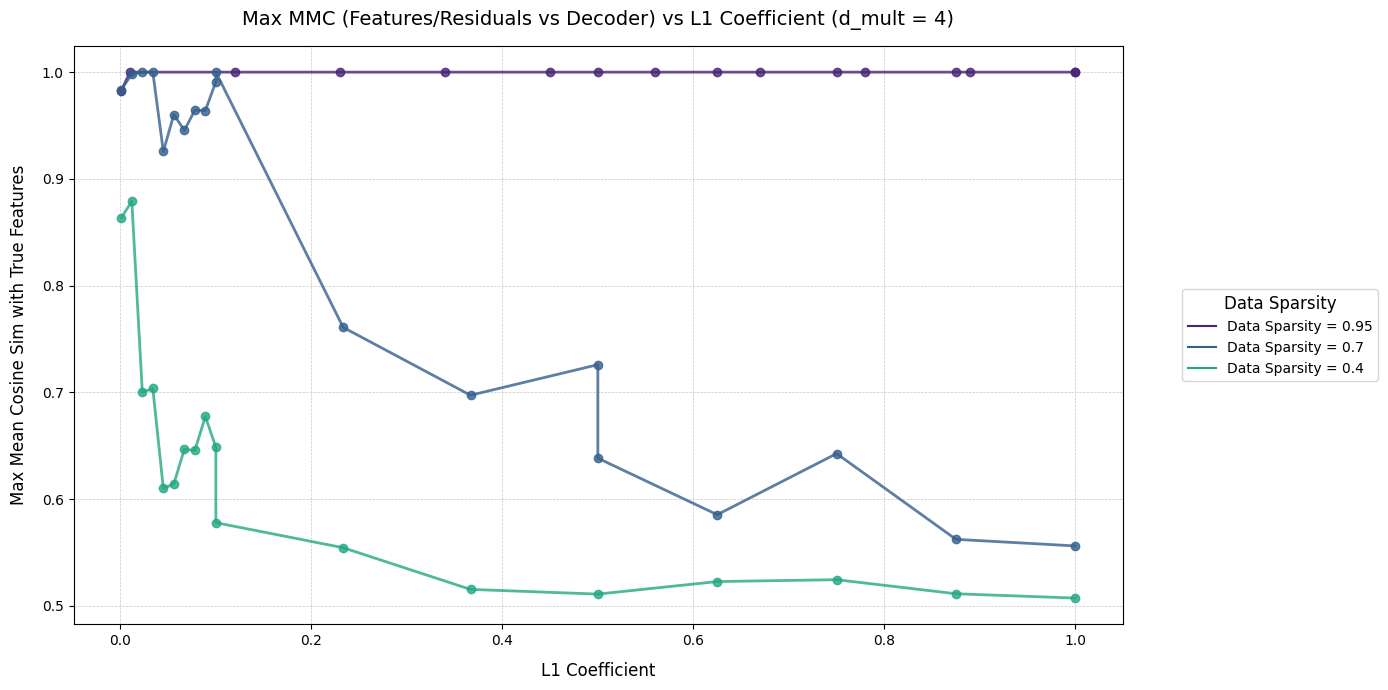
Intuitively, the model putting features into superposition means it hasn't learned a true representation of the input features. We want the features the encoder learns to be a 1:1 mapping of the true features. These graphs show the Max MMC achieved by training runs with different L1 coeffs, on data with different sparsities. Each graph shows models with a different dictionary size (1, 2, and 4, respectively). I won't try to extrapolate too much from these graphs (they're reasonably cursed), but increasing dictionary size seems to help MMC a reasonable amount when the data is sparse, and much less so when the data is dense.
Dictionary Size 1:
Dictionary Size 2:
Dictionary Size 3:
For an example of a dictionary size 2 model putting features in superposition:
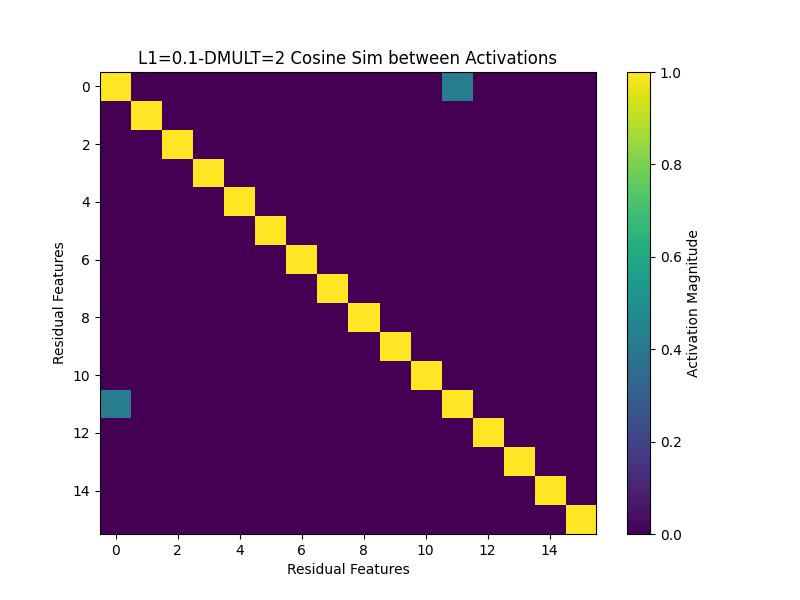
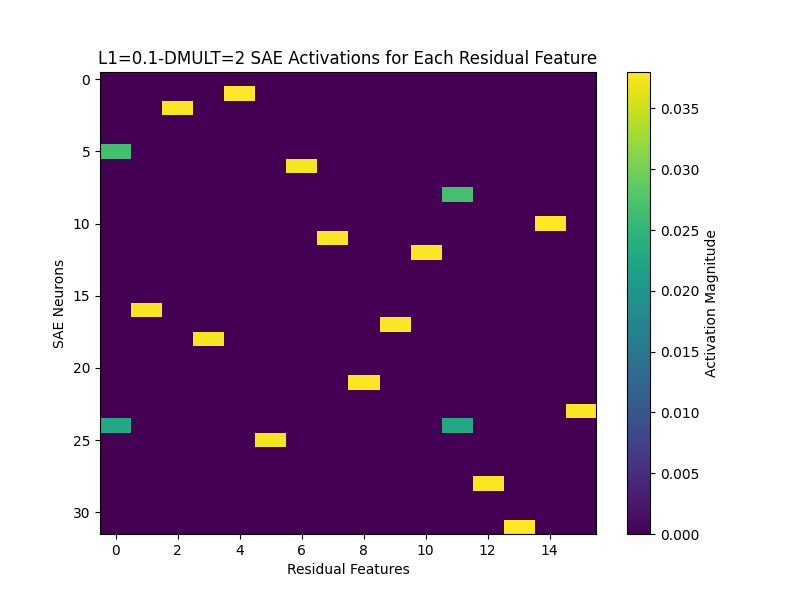
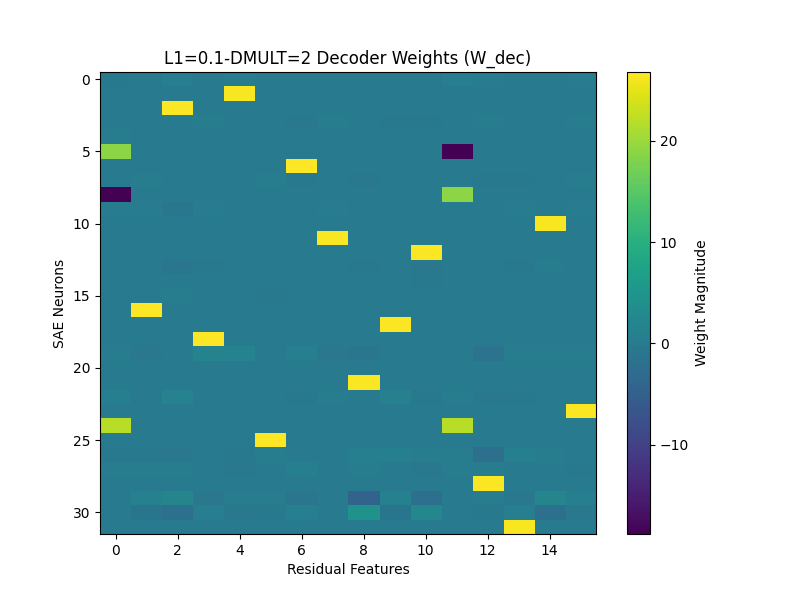
We can see in the decoder weights that features 0 and 11 each depend on the same sort of logic gate as before. Why the model chooses to do this is unclear—my best bet is because these toy models are so simple, initialization plays a huge role in whether the model will ignore the tasty alternative of superposition and find the true features. For example, the decoder weights of this model seem to jump immediately into position at initialization:
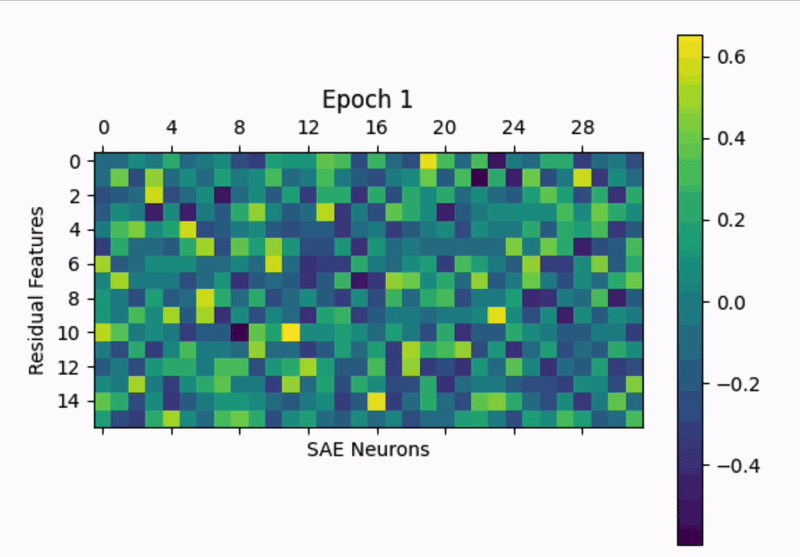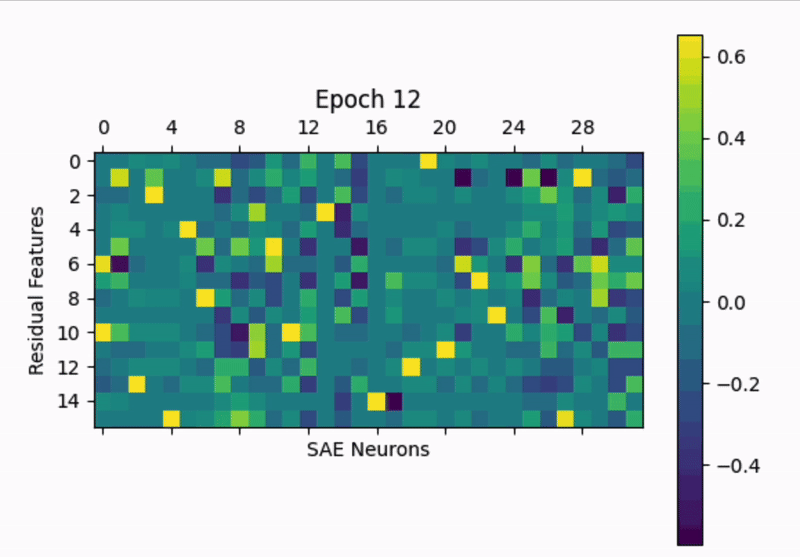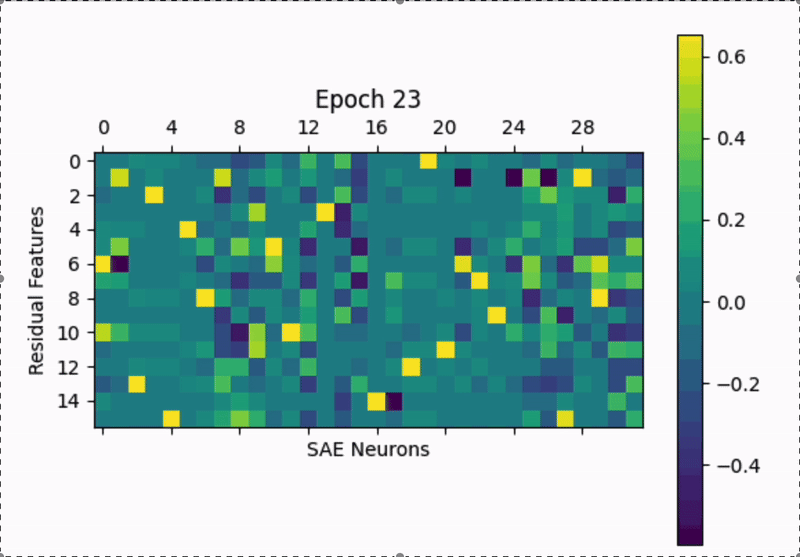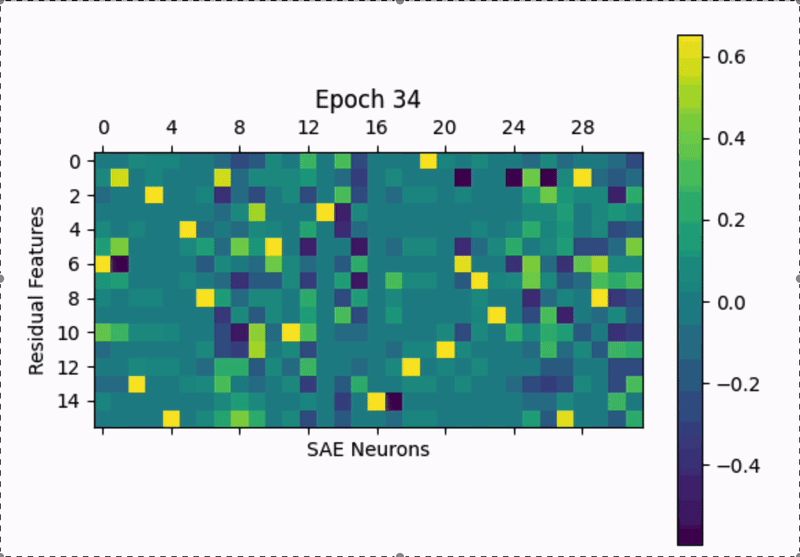
It would be interesting to look at this on a < batch timescale to see what's happening right after initialization.
Overall, the hyperparameter window when training toy models this small seems narrow. Also, there's probably a good way to work around the L1 penalty driving the hidden activation magnitude down and the decoder weights massively up that I don't know about—normalization or another penalty on decoder weight magnitude didn't seem to work, but if not, it might be an interesting problem that presents mainly in toy models but whose solution may aid larger models in some way.
Here's a dict size 1 model going crazy with the superposition! L1 wasn't high enough:
.png)
Training GIF:
.gif)